初探 inverted index
为了利用好索引带来的检索速度提升,我们首先要构建索引。主要的步骤如下:
收集所有要被索引的文档: |Friends, Romans, countrymen.| , |So let it be with Caesar|
把这些文档分为一个个单词的列表: |Friends|, |Romans|, |countrymen| , |So|...
做一些预处理,得到一系列 normalized tokens: |friend|, |roman|, |countrymen| , |so|...
为每个单词出现的文档作索引,构建 inverted index。
之后我们会对处理进行更详细的说明,也就是步骤 1-3。在那之前你只需把所谓的 tokens 或者 normalized tokens 当作是单词就好了。现在我们假设前三步都已经完成了,然后我们基于排序, 构建 inverted index。
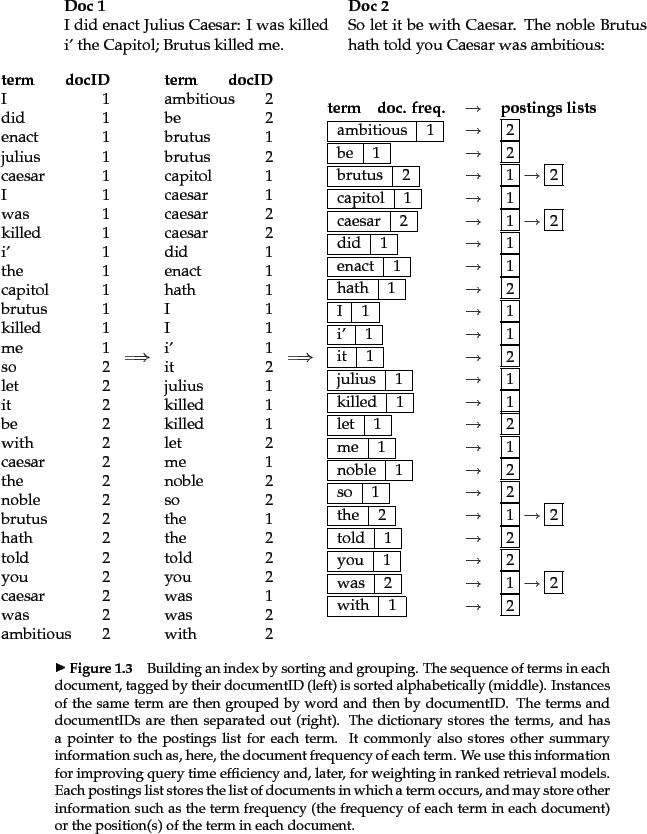
对于每一个文档而言,我们给它一个独一无二的标志符(docID)。在索引构建的时候,第一次碰到的文档我们直接赋予它一个整数就好。索引的输入是一系列文档的 normalized tokens,也就是很多 term 和 docID 的组合。最核心的一步是把所有 term 都以英文字母顺序进行排序,如上图所示的那样。一个单词在一个文档里如果出现很多次,我们只存一个。由于一个 term 一般都只出现在某些文档内,所以这样的数据组织形式减少了索引量。这里的 dictionary 还纪录了一些统计数据,比如含有某个 term 的文档的个数。对于那些简单的,基础的布尔检索引擎这可能并不是很重要,但这些数据会在之后帮助我们提高检索效率,也会被那些排名的检索模型使用。之后把 postings 按照 docID 排序。这为有效地处理查询提供了效率基础。在面对某些特定的文本处理时,这样的结构在效率上可以说是无可匹敌的。
我们存储 dictionary 以及 postings lists。后者数据量更大,一般前者都是存储在内存中,而后者是在硬盘内,后面我们还会提到如何优化这两者的存取效率。对于 postings list 来说该使用什么样的数据结构呢?固定长度的数组可能有些浪费,因为有的单词只出现在某些文档里,数量差异很大。对于 in-memory 的 postings list,两个比较好的选择是单链表和变长数组。前者插入更新的效率很高,并且可以扩展为 skip lists。变长数组则是胜在存储空间的有效利用,以及对连续内存的使用使得访问速度很快。额外的指针实际上可以作为 lists 的 offsets。如果数据更新并不是很频繁的话,变长数组比较好。我们也可以结合单链表和变长数组一起使用。当 postings lists 存在硬盘上的时候,they are stored (perhaps compressed) as a contiguous run of postings without explicit pointers,为了最小化 postings list 的大小以及 the number of disk seeks to read a postings list into memory。